Estimativa de indicadores socioeconômicos a partir de imagens de satélite na área NEXUS
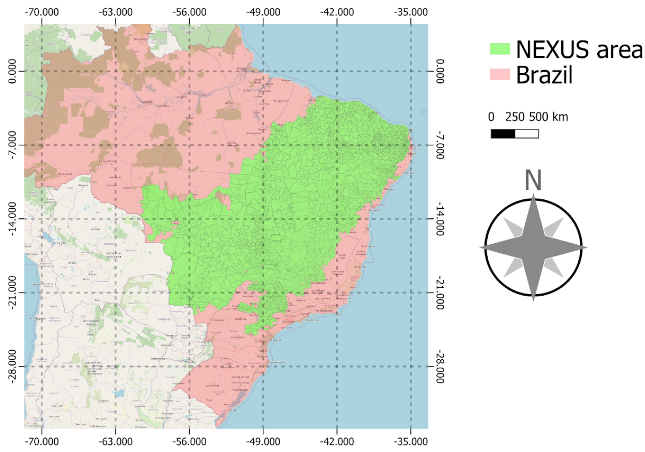
A área NEXUS corresponde a aproximadamente 40% da área do país.
O projeto Parsec tem por objetivo aplicar técnicas de Data Science e Aprendizado de Máquina voltadas para aplicações de gerenciamento e preservação da biodiversidade mundial. Em parceria com a Universidade de São Paulo e o Instituto Nacional de Pesquisas Espaciais (INPE), está sendo conduzido um estudo na área NEXUS, uma região de aproximadamente 3,4 milhões de quilômetros quadrados dentro do território brasileiro, cobrindo as bacias hidrográficas do Rio São Francisco e Rio Parnaíba.
O projeto de formatura auxilia neste estudo e propõe, inspirado em trabalhos semelhantes realizados no continente africano em anos anteriores, a estimativa de indicadores de renda, longevidade e alfabetização em toda esta área, utilizando imagens de satélite disponíveis publicamente pela API do Google Earth Engine. A contribuição deste trabalho é a criação e documentação passo a passo de uma metodologia para estimar indicadores no território brasileiro através do treinamento de modelos de Deep Learning utilizando imagens de satélite, além de propor um protótipo de uma plataforma interativa na Internet para a visualização dos indicadores estimados no mapa brasileiro.
O trabalho também contribui com a criação de um novo conjunto de dados, originado da mescla de um conjunto contendo mais de 100 indicadores socioeconômicos fornecidos pelo INPE e as informações administrativas, geográficas e geométricas dos setores censitários brasileiros fornecidas pelo IBGE.
Modelos de Deep Learning foram treinados usando o backbone de uma ResNet-18 para estimar indicadores socioeconômicos usando imagens multiespectral e noturna. Observou-se que os experimentos multiespectral eram apropriados para prever os valores alvo sobre o conjunto de dados proposto, enquanto os modelos usando apenas luzes noturnas desempenharam abaixo das expectativas devido a limitações de dados. Tendo em vista os resultados obtidos, entende-se que a metodologia proposta por este trabalho é adequada para a estimativa de indicadores socioeconômicos no cenário brasileiro.
O projeto demonstra a possibilidade de estimar indicadores socioeconômicos a partir de imagens de satélite para o caso brasileiro. Os modelos permitiram uma série de experimentações em imagens multiespectrais e noturnas levando ao entendimento das suas relações com os indicadores socioeconômicos e, para para as bandas multiespectrais, a correlação obtida entre os indicadores preditos e os reais é de até 42%, o que comprova a capacidade preditiva dos modelos no dataset proposto.
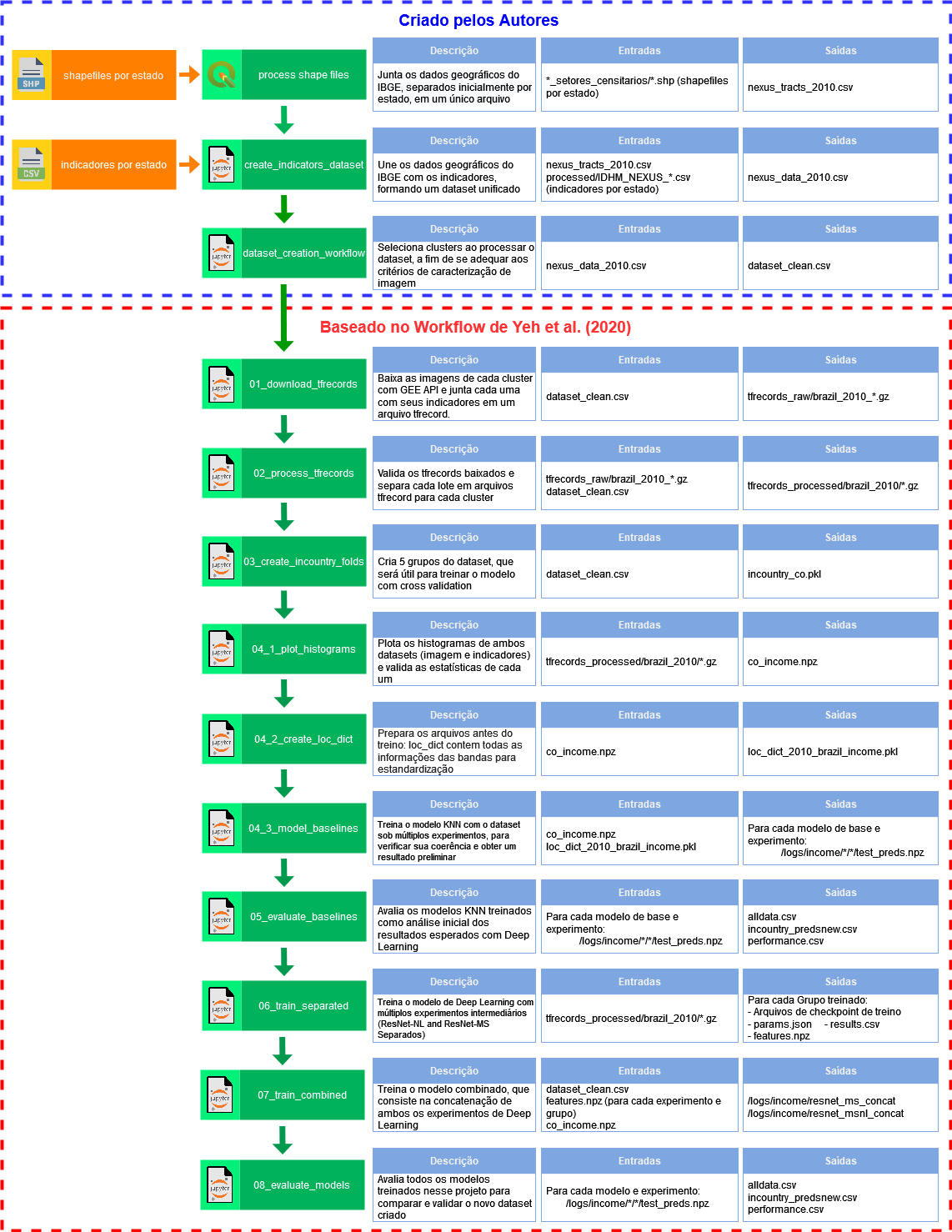
Descrição da metodologia proposta.
A parte do workflow desenvolvida pelos autores parte da obtenção e filtragem de indicadores na granularidade de setores censitários. Os 3 indicadores considerados como relevantes para estudar o desenvolvimento socioeconômico de comunidades são longevidade, renda e alfabetização. Em sequência, é realizada a seleção das regiões das imagens de satélite exige um critério rigoroso com condições que visam a garantir um modelo não enviesado e redução do custo de armazenamento: (a) cada imagem deve representar apenas um tipo de setor: urbano ou rural, (b) estes dois tipos devem estar disponíveis na base de dados em uma proporção que retrate a realidade, (c) uma determinada região só deve estar presente em apenas uma imagem selecionada. O projeto propõe duas estratégias para a seleção: Random Sampling e Neighboring Graphs.
Já se baseando no workflow proposto pelo artigo de referência, Yeh. et al (2020), as imagens dos clusters selecionados são coletadas por meio da API do Google Earth Engine, informando seu centróide, escala (30 metros/pixel), resolução (224 x 224 pixels) e ano (2010).
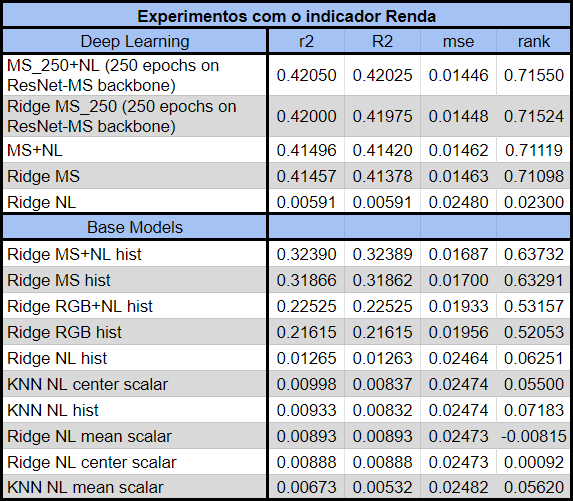
Os experimentos de Deep Learning estimam índices de riqueza em diversos países Africanos por meio de 3 redes neurais: MS, NL e MS+NL. A estrutura de MS+NL (Figura 2) apresenta entrada dupla: imagens de satélite diurnas (MS) e imagens noturnas (NL). O modelo conta com dois backbones de Resnet 18 pré-treinados para a extração de features das imagens. A camada fully connected combina as informações extraídas das entradas para uma regressão de Ridge. A avaliação da capacidade do modelo de explicar os indicadores estimados se dá por 4 métricas: coeficiente de correlação de pearson (r²), coeficiente de determinação (R²), mean squared error (MSE) e correlação de spearman (rank).
Orientação e Coorientação
Prof. Dr. Pedro Luiz Pizigatti Corrêa
pedro.correa@usp.br
Dra. Marina Jeaneth Machicao Justo
machicao@usp.br